Creating a Time Series Model
Creating a Time Series model is more complicated than the models that we have described in previous sections. This is due to the size and structure of the data, combined with the computationally intensive nature of the analysis. The data is stored in multiple files, typically in multiple directories. This data complexity and scale compels the use of parallel processing to reduce the model creation time. Unfortunately, our cluster’s batch environment increases complexity through the need for additional High Performance Computing (HPC) parameter choices, uncertain wait times in the job queue, and potentially long processing times. All these factors are at odds with an interactive interface. Consequently, our time series wizard is designed to collect all the necessary information, then autonomously launch the analysis and finish the model creation. You are free to do other things while it completes, although we do provide a means to remotely check on the status of your job through the Slycat™ interface.
To access the wizard, go to your project page, click on the green Create button and select New Timeseries Model from the dropdown list. A dialog for walking you through the process will then pop up, as shown below. The first page identifies the format of the time series data (see Time Series Data above) and the location of the ensemble’s table file. The assumption is that time series data is large and difficult to move, so it will be located on the same remote HPC machine where it was generated. Consequently, we do not provide a Local option, as we do for other model types.
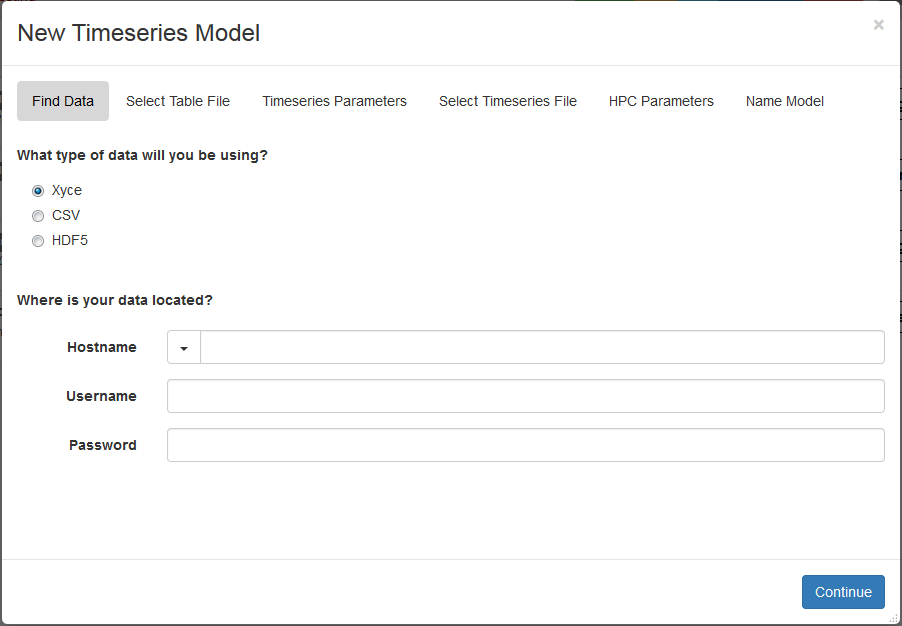
Initial dialog screen in Timeseries model creation wizard.